De vijf belangrijkste aandachtspunten bij de ontwikkeling van een data lake
Veel organisaties bezitten een schat aan historische data. Van klantdata tot financiële data en van onderzoeksdata tot data over social media. Vaak zit deze data opgesloten in verschillende systemen en applicaties. Een klassiek IT-vraagstuk is hoe deze data gecombineerd kan worden tot centrale inzichten. Aan de hand van deze inzichten kunnen betere keuzes worden gemaakt of een hogere efficiëntie worden bereikt.
Een regelmatig gebruikte oplossing om databronnen te combineren is het ontwikkelen van een data lake. Een data lake is een vorm van dataopslag waarbij data afkomstig van meerdere bronnen initieel in ruwe vorm wordt opgeslagen. Op basis van deze ruwe data kan bijvoorbeeld data verrijkt worden, kunnen gecombineerde analyses worden uitgevoerd, of processen worden aangesloten die gebruik maken van de gecombineerde data. Data lakes worden vaak genoemd als versneller op gebieden zoals data science en machine learning. Ondanks de aantrekkelijke gedachte van alle data centraal op één plaats, is de afgelopen jaren duidelijk geworden dat data lakes geen magische oplossingen zijn. Analistenfirma’s zoals Gartner en Forrester bevestigen al een aantal jaren dat een opvallend aantal implementaties geheel of gedeeltelijk mislukt zijn door verkeerde verwachtingen of verkeerde keuzes1). Vanuit Luminis komen wij dit ook tegen in de markt. Vaak ontstaan implementatieproblemen door verkeerde verwachtingen in combinatie met een te grote focus op de technologie. Deze paper helpt u om een afgewogen keuze te maken of een data lake passend is voor uw situatie. Vanuit zowel theorie als praktijk nemen we u mee in enkele afwegingen, randvoorwaarden, kansen en risico’s. Ook schetsen we alternatieve oplossingen voor een data lake. Hierdoor bent u beter in staat om een keuze te maken en kunt u de juiste stappen zetten om succesvol te zijn in de uitvoering van uw datastrategie.
De oorsprong van data lakes
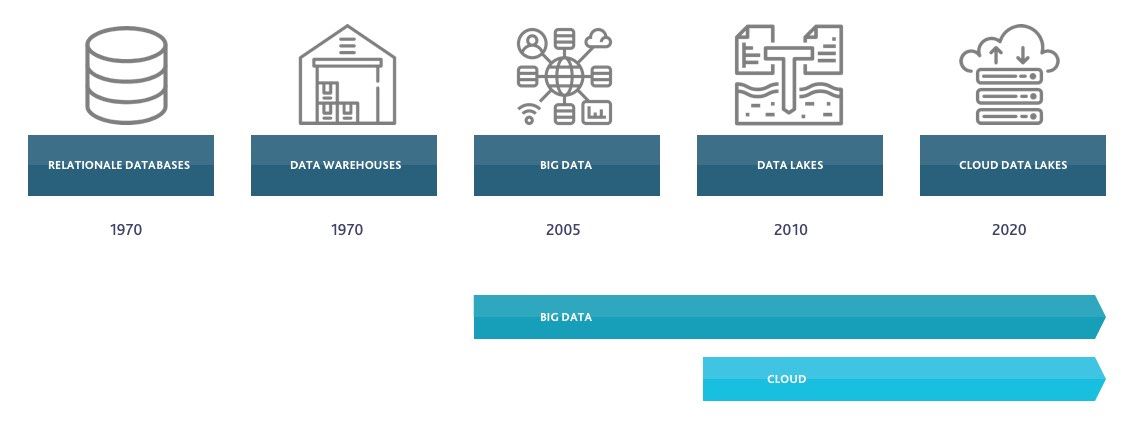
Tot 2005 was verreweg de meest gebruikte opslagvorm een relationele database. Meer dan 30 jaar vulden relationele databases de meeste ontwikkel- en gebruikersbehoeften prima in. Met name door de rol van het internet groeide de hoeveelheid gegenereerde data sterk en was er ook meer behoefte aan analyses van deze grote hoeveelheden data. Bijvoorbeeld in het geval van websites met veel gebruikers of veel interacties. De opkomst van technieken zoals NoSQL en Bigtable markeerden in 2005 daarom de start van het ‘big data’-tijdperk. Relationele databases zijn heel erg goed in het verwerken van transacties. Dit wordt ook wel Online Transaction Processing (OLTP) genoemd. Nieuwe opslagmethodes zoals Bigtable en Hadoop zijn door hun structuur en architectuur veel beter geschikt voor opslag, bewerking en analyses van big data. Dit wordt ook wel Online Analytical Processing (OLAP) genoemd. Naast backoffice applicaties werd steeds vaker een datawarehouse opgezet voor analyse-doeleinden, omdat de meeste enterprise applicaties niet geschikt zijn voor grootschalige en complexe analyses. Data vanuit applicaties (Finance, logistiek, CRM etc.) komt samen in een datawarehouse, waar de data gestructureerd wordt opgeslagen. In datawarehouses wordt data zo veel mogelijk in structuren zoals tabellen opgeslagen, voorzien van de juiste metadata, volgens strakke definities en herleidbaar tot de bron. De groei van het aantal datawarehouses zorgde er ook voor dat steeds meer organisaties Business Intelligence rollen of afdelingen creëerden. In 2010 kwam James Dixon, CTO van analyticsplatform Pentaho, met de nieuwe term ‘data lake’. Hij gebruikte hiervoor een metafoor. De gestructureerde data in datawarehouses vergeleek hij met flesjes water. Allemaal gestandaardiseerde afmetingen en kwaliteit, en klaar voor gebruik. Voor sommige toepassingen is dit prima, maar voor andere toepassingen zijn flesjes water helemaal niet handig. Voor data science of voor exploratief onderzoek kan het handig zijn om toegang te hebben tot een grote hoeveelheid water, zonder beperkingen van een flesje. Zo’n meer van data – oftewel data lake – biedt gebruikers directe toegang tot de ruwe en ongestructureerde data, zodat de gebruikers hier zelf hun toepassing mee kunnen verzinnen. De verplichte dataschema’s binnen een datawarehouse zijn een essentieel verschil met data lakes, die in de basis met ruwe data werken2). Tien jaar later is de term data lake een architectuurpatroon geworden dat regelmatig wordt toegepast binnen organisaties. Er is een heel ecosysteem ontstaan van bedrijven die onderdelen van data lakes of kant-en-klare data lakes leveren. Door de opkomst van cloud-infrastructuren vanaf 2010 worden steeds meer data lakes in de cloud gehost, of ontwikkeld op basis van cloud services. De verwachting is dat op termijn alle data lakes in de cloud zullen draaien. Cloud-infrastructuren bieden naast lage opstartkosten en vrijwel onbeperkte opslag ook grote bewerkings- en rekencapaciteit voor bijvoorbeeld machine learning-toepassingen.
Vijf aandachtspunten bij de ontwikkeling van een data lake
Ik heb onlangs een whitepaper geschreven met verschillende aandachtspunten bij de ontwikkeling van een data lake. Aan de hand van bedrijven zoals Amazon en Epic Games komen ook verschillende praktijkvoorbeelden voorbij. U kunt de whitepaper hier gratis downloaden.

