
Classificatie van bewakingsvideo’s met TensorFlow en Python
Jullie verwachten natuurlijk weer een saai verhaal over Agile, over requirements, over klanten die niet weten wat ze willen, of zoiets dergelijks. Maar nee, Als Bert Ertman op de DevCon mag vertellen over zijn deurbel mag ik vertellen over mijn beveiligingscamera.
We hebben af en toe wat last van vervelende jongeren, maar ook als er mocht worden ingebroken dan zijn beelden wel handig. En als je dan toch Unifi netwerkspul in huis hebt is de stap snel gezet naar een Unifi camera. Ik vond deze wel leuk om mee te beginnen. De installatie was makkelijk; tenminste na een lang gevecht over Java-runtimes.
De software achter de camera is motion triggered, dus bewaart alleen opnamen als er in de actieve zone(s) genoeg beweging wordt gezien. Maar ja, bladeren bewegen ook, dus dan heb je stapels onnodige opnamen; regendruppels bewegen, dus weer, nutteloze opnames. Ja, je kunt zones opgeven, dus om die boombladeren kun je heen, maar de schaduw van die bladeren valt natuurlijk in de zones die je wel wilt hebben, en ook schaduwen bewegen. En je kunt opgeven hoe gevoelig een zone is, maar te laag instellen betekent dan weer een opname missen. Kortom: ergernis.
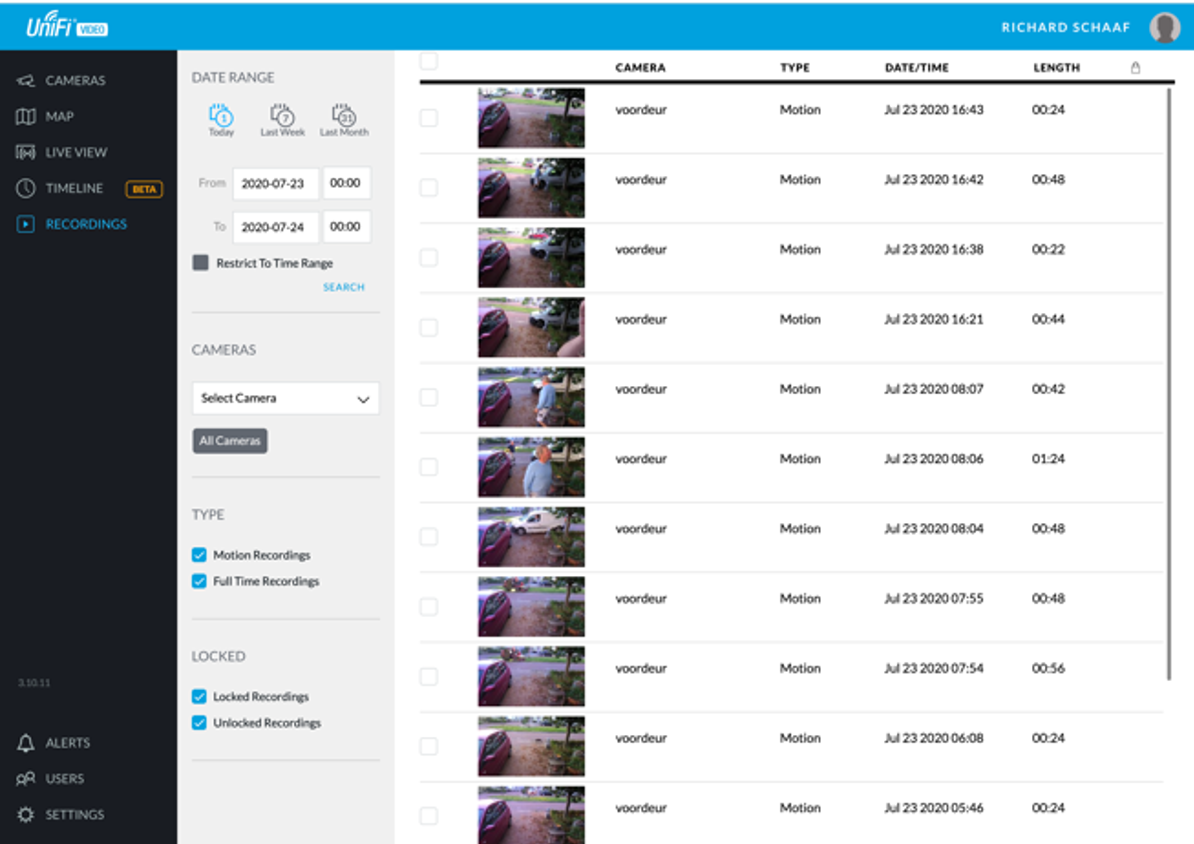
Maar wat bleek, informatie wordt weggeschreven in een matig beveiligde MongoDB instantie, en van elke opname wordt het resultaat van de motion detectie als PNG weggeschreven en bovendien een snapshot bewaard. En dus kunnen techneuten (zoals ik stiekem ook nog ben) aan de slag!
Al snel ontstond dit (blauw=standaard, groen=nieuw):
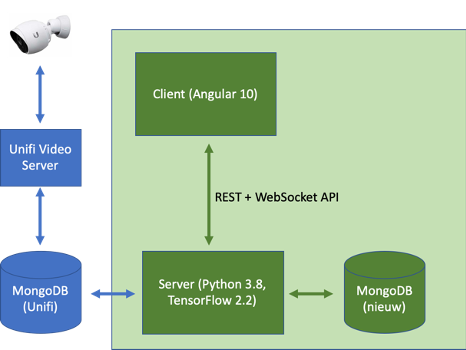
Overigens is dit sterk vereenvoudigd, maar het geeft een idee. De Python-applicatie handelt een aantal zaken af:
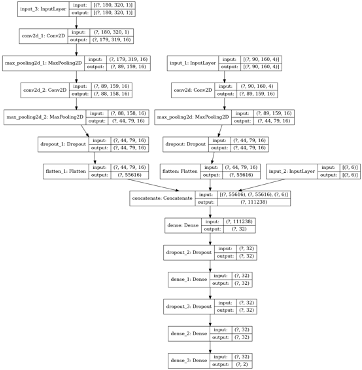
- Als er een nieuwe opname wordt gedetecteerd, dan wordt deze beoordeeld door een Tensorflow (Keras) AI. Voor nu is de layout van het model zoals in het plaatje hierboven. Het resultaat wordt bewaard. Als de server in “trust” mode staat (tijdgestuurd), wordt een als onnodig beoordeelde opname meteen verwijderd.
- Via de client kun je opnamen bekijken, samen met de beoordeling van de AI, je kunt dan een eigen beoordeling opgeven en deze opslaan. Uiteraard met de nodige shortcuts.
- Als de AI een andere beoordeling heeft dan de gebruiker komt de opname op een aparte lijst om nog een keer te kunnen beoordelen; ik klik nog wel eens op een verkeerde knop namelijk, en ook uit de training (zie hierna) komen soms verschillen naar voren die fouten in de AI kunnen zijn, of misclassificaties.
- Iedere nacht traint de AI zichzelf opnieuw, uit een aantal Tensorflow-modellen wordt de beste gekozen en die wordt de komende 24 uur gebruikt.
- Na een training wordt opnieuw bekeken waar de beoordeling van de gebruiker anders is dan van de AI. Verschillen, voor zover de gebruiker er niet al eerder een keer over heeft geoordeeld, komen op de eerdergenoemde “error” lijst.
- Natuurlijk kun je opnames zoeken, hetzij op ID, of op een datum-range.
- Na een instelbare tijd wordt er opgeschoond, dus opnames die oud zijn worden verwijderd. Dit tenzij de gebruiker heeft aangegeven dat de opname bewaard moet blijven.
- De client werkt natuurlijk op desktops en op telefoons.
Dat klinkt leuk, maar voor je zover bent dat het werkt ben je wel een tijdje verder. Ik moest Python leren, MongoDB temmen, Tensorflow/Keras begrijpen, en dan natuurlijk kunnen praten met de Unifi server (want ja, video sla je natuurlijk per 2 seconden op in een onduidelijk formaat….), systemd goed aan het werk krijgen, logrotate goed inrichten… En voor je het weet ben je zo een aantal avonden/weekenden verder.
En als het dan allemaal lijkt te werken kom je erachter dat dit allemaal best veel geheugen kost. Mijn arme servertje had maar 8GB en dat was echt te weinig als je met veel opnamen wilt trainen. Maar dat was wel het maximum volgens de fabrikant. Gelukkig blijkt hij het ook te doen als je er 16GB in prikt. En dan werkt het trainen wel…. net aan….
Al met al ben ik best tevreden. Ik ben geen UX guru, maar de UI werkt snel en makkelijk. Updates van de server komen binnen no-time via de websocket bij alle clients, nieuwe opnames verschijnen direct (zonder polling), en bovenal, de nauwkeurigheid is goed.
Wat kengetallen voor de nerds onder ons:
- >99.5% nauwkeurigheid van de AI
- >50% van de opnamen is onterecht en wordt nu als zodanig herkend
- ~100 opnamen per camera per dag
- >12GB geheugengebruik bij training van het model
- 30-60 minuten trainen per modelvariant (op de MacBook ongeveer de helft daarvan)
- >2500 regels Python
Ik ben tevreden in elk geval, en belangrijker, ik heb weer een heleboel geleerd de afgelopen tijd. En het is ook denk ik meer toepasbaar, bijvoorbeeld in meldkamers waar een bewaker niet alle video kan bekijken. Daar kan iets als dit de belangrijkste opnamen tonen en de rest verbergen bijvoorbeeld.
Een aantal lessen, deels niet nieuw:
- Python valt eigenlijk best wel mee, tenminste zo lang je niet de hele tijd tussen Typescript en Python heen en weer hoeft te schakelen, en dat doe je juist wel als je iets als dit aan het maken bent.
- MongoDB is te doen, maar liever geen handmatige queries uitvoeren want je wordt gek van de haakjes.
- TensorFlow is cool! Maar het maken van je trainingsets kost $*$&#%*-veel tijd en moeite voordat je een goed resultaat hebt.
- Voorbeeldcode is leuk, maar als je echt iets wilt doen is het altijd veel ingewikkelder. De standaard TensorFlow classificatie voorbeelden werken prima. Tot je net iets meer wilt, dan ben je uren en honderden regels code verder.
- Goldplating is leuk, maar kost ook tijd. Had ik het dynamisch inladen van de server-configuratie nu echt wel nodig? Of runtime replacement van classes? En is het trainen van 8 modellen per nacht waarvan er eigenlijk maar 2 of 3 levensvatbaar zijn “gewoon omdat het kan” niet overdreven? En is rekenen op N camera’s door je hele code heen terwijl je er maar 1 hebt niet wat te veel van het goede?
- Een project als dit is nooit echt “af”; de positionering van de “play” buttons werkt nog niet lekker op mobiel, de navigatie met tabs is maar “meh”, de kleuren kunnen beter, mijn PyLint score is nog niet 10.0/10.0. Moet ik niet een build-straat maken? En misschien iets doen met ketentesten? Of is dit allemaal “goldplating”?
- En de belangrijkste les: het blijft leuk om nieuwe dingen te leren. Dat wist ik natuurlijk al, maar het is een mooie bevestiging. Ik wil nooit stoppen met nieuwe dingen ontdekken, zelfs (of juist) als ze buiten mijn normale werkzaamheden vallen!
 .
. 
Meer weten over wat wij doen?
We denken graag met je mee. Stuur ons een bericht.