

Vector Databases
Data can be represented in many ways. Take an analog calendar as an example, you can see all the days stored on lines that represent the weeks and those weeks are packed on a month. Group 12 of these packs and you have a full calendar. Add some cat pics, update the data and you can sell it every January. This is a silly example, but I hope you get the idea behind this.
We have been storing data since the writing was invented. First writings were not epic poems, but just a list of objects in a warehouse or shiploads. Since the 60s we have used databases to store and manage data. It is more efficient, more consistent, more secure, more scalable, etc. That said, the way the data is stored on these databases will directly affect the benefits offered. Continuing with the first example, calendars are efficient because located on time faster and consistently. It is more pragmatic to daily life to know that today is the 23 of August and not the 235th of 2023.
As time passed, the needs and the benefits you can get from databases changed and expanded. Let’s take relational databases as an example. If you store “Math 101” on the table subjects and create a relation with the table subjects you will be able to get all the students enlisted in the course. This “relation” creates a feeling of belonging, something that is not there, is not real, but helps us to create meaning of the data and to organize it with a purpose. It helps us to recreate the model we have in our minds.
Introducing Vector Databases
This year vector databases have been a hot topic. We will talk later why and which specific problems they solve, but at this moment, the important thing is to understand what they store, the vectors.
Vectors are mathematical objects that represent direction and magnitude in space. We will have problems if we try to imagine more than 3 dimensions, but computers don’t have that problem, in fact, vectors al highly versatile and almost everything can be represented as a vector. Let’s say that you have an image and you want to store it. One way to do it is to split the image into pixels and assign a number based on a scale. By doing this we will have another way of representing the data, instead of having an image we have a high-dimensional vector.
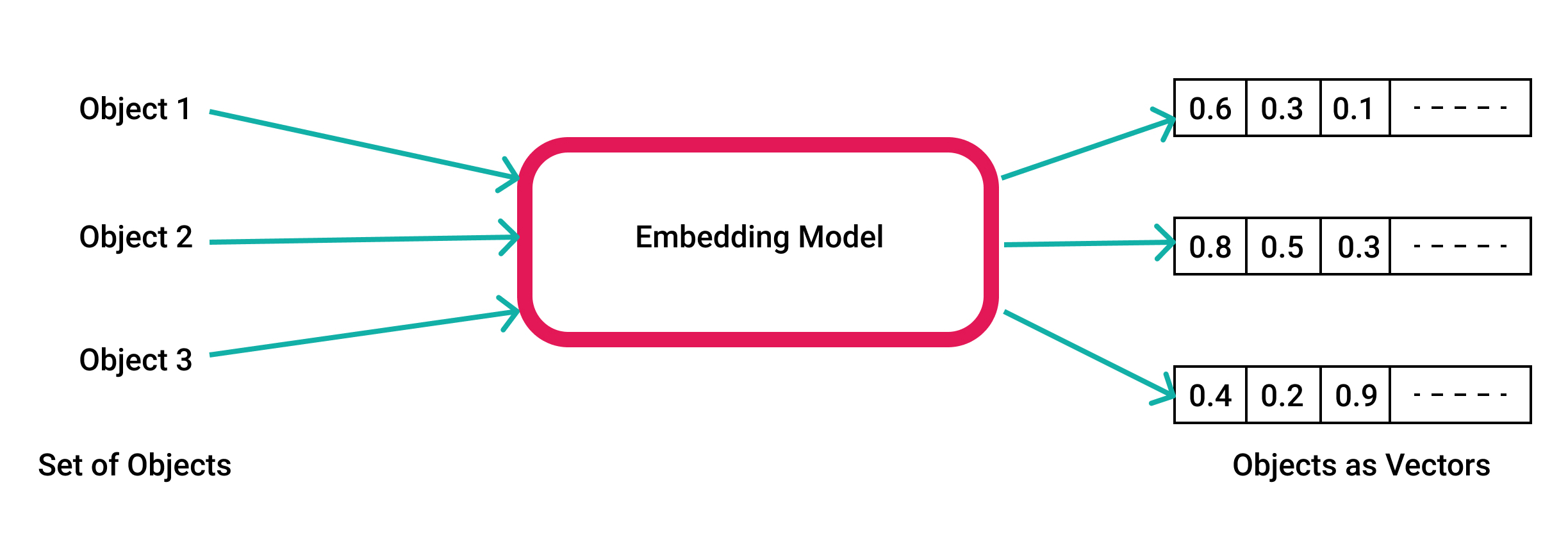
So, as you probably already imagined, vector databases are just databases made for storing vectors. But weren’t vectors just numbers? Why cannot just store it on an SQL database?
Well, the short answer is that you can and (even better news) there are databases that you know and have support for vectors, like OpenSearch (via k-NN), PostgreSQL (via PGVector) or ElasticSearch (via Knn search). That said, you will probably lose all the benefits of using dedicated vector databases.
Benefits of vector databases
Imagine you have a basket with fruits. You pick an orange and you have to pick another fruit similar to the orange. Will you pick an apple? Probably not. Maybe a lemon? Well, both are acid and the skin is similar. Vector databases can help you with this task.
Semantic search allows you to get values that are more related to others depending on the context. If relational databases establish a relation between the different tables, which creates a sense of belonging, vector database does the same for similarity. The examples in this picture can help you to get a deep understanding of this concept.
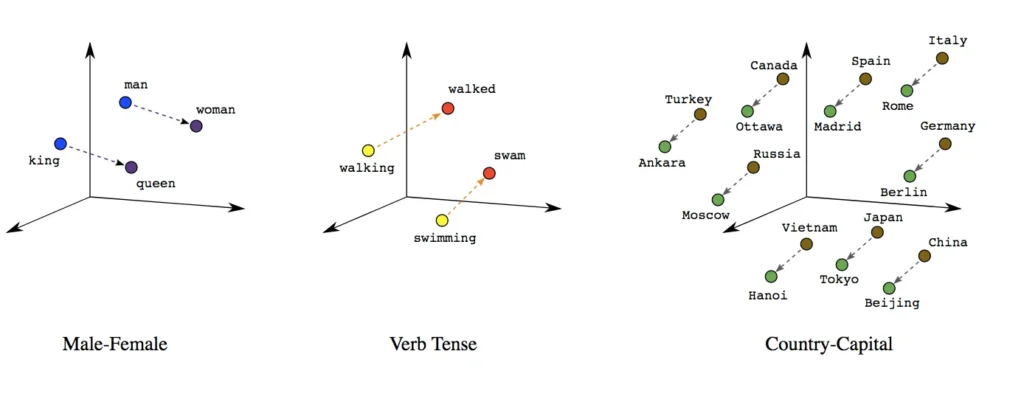
Similarity search is one of the strongest points they have, and it’s why databases are a hot topic right now because it allows you to store text (as a vector) and based on that use LLMs like ChatGPT or LLaMA to ask questions that can be answered based on a simulated context or just retrieve similar documents. Some databases that get especially good results are Weaviate, Pinecone and DeepLake. On the other hand, if we want a fast implementation with Python, you could use Chroma.
The same logic that applies to similarity can be used to get recommendation engines. These engines provide custom suggestions or recommendations to users based on their preferences, behaviour, or characteristics which in this case will be stored as vectors. Weaviate (they explain how on this post) is a database especially good on this, but other mentioned databases can also fit on this.
Another useful case for vector databases is real-time geospatial search and analytics. This involves the instantaneous querying, retrieval, and analysis of location-based data. This is particularly useful in applications where time-sensitive information related to geographic locations needs to be processed and visualized quickly. Optimize routes, tracking vehicles, emergency responses, etc. are some real problems that can benefit from vector databases, and the best option for this scenario is Qdrant.
Conclusion
This blog pretends to be an introduction to vector databases. Understanding their fundamentals and some use cases is more important than just using them because everybody does. That said, we strongly encourage you to use them when working with LLMs as it is the standard right now, but make sure you are picking the right option before start developing.
If you check out the top tending repos on github, you will see that most of them are trying to create an AGI (Artificial General Intelligence), like Auto-GPT, babyagi or jarvis (Microsoft). These tools make use of LLMs and vector databases because allow them to create long-term memory, storing the prompts as vectors and using these prompts themselves to generate even more content with their own context.
Meer weten over wat wij doen?
We denken graag met je mee. Stuur ons een bericht.