

Introduction of Frank and Amy at HaystackConf USA
Last week, at the end of April 2023, I attended the HaystackConf in Charlottesville, USA. HaystackConf is the conference to participate in if you are a search relevance engineer. With over a hundred people attending on-site and more than a hundred online, this is a good representation of the almost 4000 members at the time of writing in the search relevance community on Slack.
After presenting at the online HaystackConf due to covid, this was the first time I joined the conference as a speaker. This was also my first speaker experience outside of Europe, and what a great experience it has been. This is the conference where I introduced Frank and Amy to the big public. This blog post will take you with me on my journey to the USA.
 Sunday morning, we took the plane to Washington, DC. We, because I traveled with my Buddy and old colleague Byron Voorbach from Weaviate. We rented a car to drive to Charlottesville. After arrival, we did a walk through town, ate a hamburger, and took a drink.
Sunday morning, we took the plane to Washington, DC. We, because I traveled with my Buddy and old colleague Byron Voorbach from Weaviate. We rented a car to drive to Charlottesville. After arrival, we did a walk through town, ate a hamburger, and took a drink.
Monday was Jetlag day. Besides a bit of work, we explored the environment. We went to a park to shoot some pictures, and in the evening, we attended a local meetup at the Center for Open Science: Pre-Haystack US Meetup at Center for Open Science. The meetup had two talks.
Matt Clark on COS, whose mission is to increase openness, integrity, and reproducibility of research, and their SCORE project: Systematizing Confidence in Open Research and Evidence.
René Kriegler, Director, E-commerce Search at Open Source Connections: A path to understanding and adopting evolving technologies in search.
The evening was a good warm-up for the conference—excellent discussions about the relevance of Vector databases and ChatGPT for the search relevance domain.

Tuesday, Conference Day 1
Charlie Hull welcomed everybody on-site as well as online. Next was the keynote by Trey Grainger. Always a good speaker. I liked his overview of approaching search before and moving from Sparse to Dense information retrieval. It was clear that vector search is here; having a sparse search alone is not the future. Is hybrid search just a step from sparse to dense because dense still has some issues, or is hybrid the future? Will large language models be the silver bullet? The one clear thing is that search and information retrieval are going through an exciting time.
The next talk I attended has a summary in its title: “Learning to hybrid search: combining BM25, neural embeddings and customer behavior into an ultimate ranking ensemble”. Roman Grebennikov presented his thoughts on the current hype around neural search. Roman is the primary author of the project Metarank. An interesting project if you want to use learning to rank.
The next talk was by Karel Bergmann: “Creating Representative Query Sets for Offline Evaluation”. He explained how they used offline evaluation at Getty Images. Interesting to see the scale at which they use these evaluations to optimize searching for images.
Lunch at HaystackConf is going into town and selecting a restaurant. Everybody can find something they like with the number of choices available in town. After lunch, I visited Ohad Levi. His talk is titled: “Breaking Search Performance Limits with Domain-Specific Computing”. He discussed using domain-specific hardware to improve search performance with a factor of 100. Impressive numbers that work well with specific instances of AWS machines.
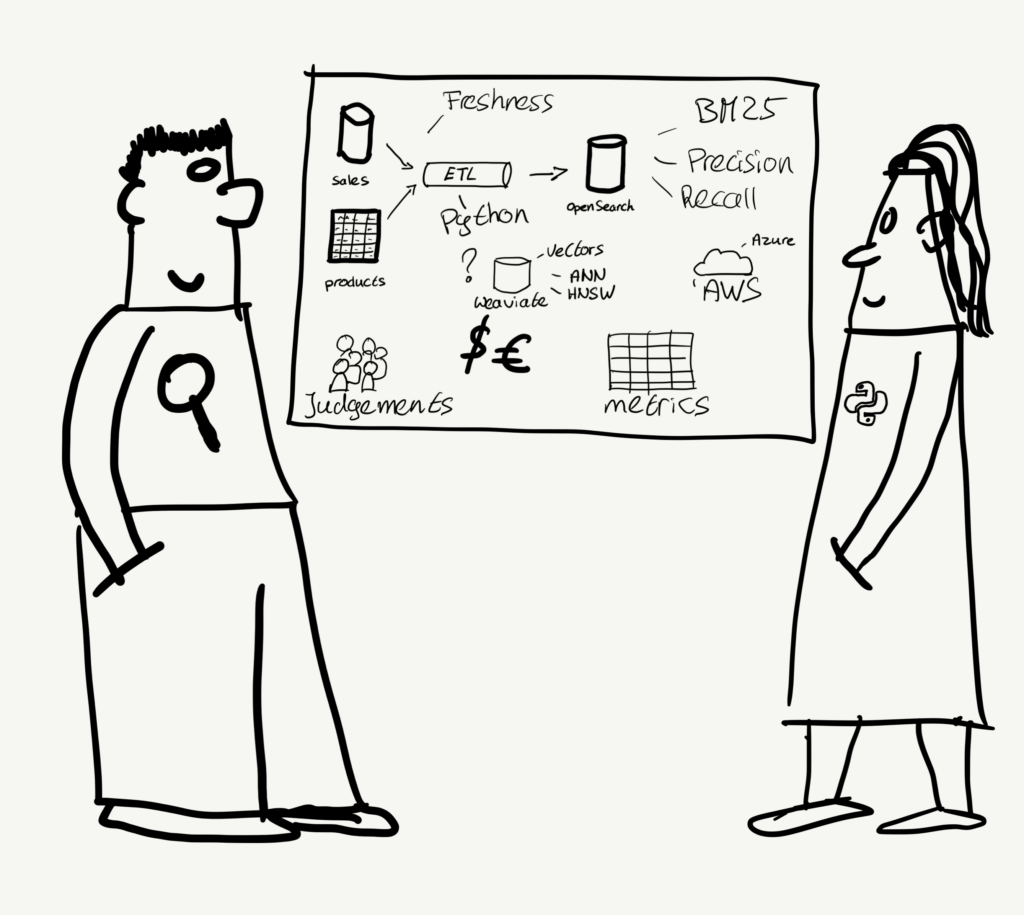
The following presentation was my own. The title of my talk is “Top 8 search topics to teach your team members”. I introduced the main characters of my presentation, Frank and Amy. During the talk, I used Frank, the search relevance expert, to explain search features to Amy, a seasoned Python developer. It was fun for me to do the presentation. I got good feedback from the audience. They liked the presentation with all the drawings and recognized the topics. Not all of them explained these topics to their team members, which was a good lesson for them.
After my talk, lightning talks followed by a reception and dinner at the Kardinal Hall. Good beer, food, and a game of Bocce. A relaxed atmosphere to talk about search topics and get to know each other.
Not everybody returns to the hotel after dinner. Charlottesville has a lot of bars to offer, and drinks are diverse, as are the people from Charlottesville.
After a satisfying day, time to go to bed.
Wednesday, Conference Day 2
The second day of the conference started off with an Ask me anything session with the authors of the book “AI-Powered Search“. Participants were Trey Grainger, Doug Turnbull, and Max Irwin. Most of the exciting questions were again about vectors and Large Language Models’ role in search. These three guys together have an incredible amount of knowledge in the search area. If you like this topic, you should read their book.
Next, I attended the talk by Jay Flack titled “Enterprise Search Relevance at Box: Simplicity”. You should not be surprised this talk is about the experience they gained at Box to supply a search feature over all the documents they have. Security and speed are very important as the number of documents is enormous. They used Solr with an exterior ranking model built with Tensorflow running on AWS Sagemaker.
Lunchtime again, and waiting for the talk by Erika Cardenas. Erika is a colleague of Byron; this is her first talk in public. Yes, she was a bit nervous. But you step into a cinema room and present a keynote plus a short presentation about the women in search. Erika’s talk was about “Building Recommendation Systems with Vector Search.” Erika did a great job. Of course, she used Weaviate for the demo application. An interesting talk about the ref2vec module for Weaviate. Go try it out if you are interested.
Next up for me was the presentation from Chris Morley. His talk is titled “Populating and leveraging semantic knowledge graphs to supercharge search.“ He was funny and had some interesting ideas, but it did not work for me. I did not really understand the point he was making. He mentioned it was more of a try-out for him; it needs some polishing if you ask me. The content is there, but the story is harder to follow.
The last presentation was from Colin Harman. The title of his talk is Stop “Hallucinations and Half-Truths in Generative Search”. I really liked his talk. He showed examples of where ChatGPT produces wrong answers. His examples using simple calculations in your question to break the results were interesting. One example where he asked ChatGPT only to consider a provided document to answer a question was wrong. Also, an example about medicine, where the answer varied the code for the medicine a bit and could even give a dangerous answer. Great closing talk for me.
The closing event for the conference was a dinner sponsored by Weaviate. I sat next to Erika and Colin. Had really good conversations. It was an inspiring evening again.

That is where the conference ended, but not the learning. The following two days, we had fun driving to Washington through the mountains and visiting Washington. We also took time to work on a sample application using Weaviate and OpenAI. Using a cross-encoder as a re-ranker for a hybrid search in Weaviate. Feeling more confident now working with Weaviate.
Call me if you are reading this and want to know more about search, vector databases, and Large Language Models. We can help you create AI-powered search solutions that help your user become effective searchers.
Stay tuned for announcements if you want to experience HaystackConf, but live in Europe and feel the USA is too far away. HaystackConf is coming to Europe again this year. Maybe to the Netherlands.
Want to know more about what we do?
We are your dedicated partner. Reach out to us.