
Resolving the paradox of cloud-native solutions: more agility without total control
Being cloud-native enables organizations to implement changes at the speed of light, but leveraging cloud technology also means giving away control. That sounds like a paradox, but it resolves once you realize that you don’t need to give away control completely. But what do you keep in-house, and what power do you give to your cloud technology and third-party software vendors? Sneak peek: focus your efforts on your core competitive edge while smartly integrating with the non-differentiating stuff.
Don’t feel like reading? Watch this post (and more) as a video
Last week, I joined an XPLUS Breakfast Session to talk about how organizations can leverage cloud technology to shorten their time-to-value. Our client Ctac, personified by Ivo van der Raad, started the webcast by presenting their cloud plans for their XV Retail Suite. Exciting stuff, so feel free to come back here later and watch the session first.
I used my ten minutes to look at this typical retail challenge from a technical point of view. This blog post is an extended transcript of that presentation, with the upside that you don’t have to look at my face the whole time. Win-win.
Now, back to resolving the paradox.
The need for speed
Before I get into the technical stuff, let me briefly explain the problem in business terms first.
Consumer-facing software is moving faster than ever, with customers expecting increasingly safer, better, and faster solutions. Evolving technology is a significant enabler and driving force behind this acceleration. Successful solution providers combine tailor-made software, third-party packages, and SaaS offerings to craft the stuff their customers crave. That’s impressive! But it also sounds like a magic trick. An illusion, if you will. How is it possible to hand over so much control to external parties and maintain the agility needed to compete in the market?
Smart integration, that’s how.
The integration challenge: from central management to distributed control
Three focus areas emerge if we compare this current reality to the world of a decade or more ago.

The first is a shift from centrally managed, self-hosted application landscapes to distributed solutions. Let’s say an organization has a few systems containing customer data and many custom-made services and clients that integrate with them. A decade ago, their IT department would have self-hosted this custom and third-party software combination, employing a variety of service buses, API endpoints, and direct messaging solutions. They would have slowly evolved the landscape whenever they had to build new functionality or add a new system.
Thanks to the advent of Software as a Service, IaaS, PaaS, and high-level cloud services, organizations need to move much faster to keep up. Their landscapes are fragmenting. Keeping expertise in-house is costly and reduces innovation budgets.
Here emerges the second challenge. The technology market’s shift to SaaS and managed cloud services, combined with the never-ending desire for better customer functionality, forces companies to gain traction and move more dynamically.
That can only mean, whether they want to or not, that builders need to let go of some of the control they used to have. But they still need to integrate everything. They must learn how to leverage new ways of integrating their building blocks, and I propose they use those giant vendors’ shoulders and shift a lot of the heavy lifting onto the public cloud and SaaS providers’ offerings.
The cloud-native integration paradox: more agility, less control
All right, now we are looking at what seems to be a paradox. Organizations need to be in total control, but at the same time, they need to hand over some control to external parties. What gives?
Organizations need to be able to move fast to respond to the changing needs of their customers. They must deliver changes into production quickly, see what works, and continually adapt based on what they learn. To do so, they require the technology and skills to precisely determine what their customers want and give it to them. They must practice deploying changes rapidly but safely. And they need to develop a software delivery process that is solid and improving over time. In other words, organizations need to be in complete control.
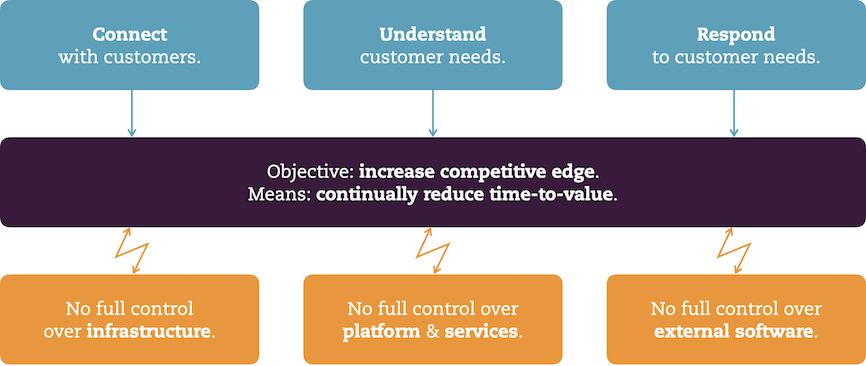
However, I claim that they hand over some control to external parties. That means they no longer have total power over all the underlying infrastructure or the services and software they need to combine into a solution.
So here we have the paradox of delivering value, end-to-end, through software using the cloud and software as a service: the need for more agility while simultaneously leveraging the offerings of external vendors.
Luckily, this is not an actual paradox. It is possible to increase agility while giving up control, but the trick is to be smart about it. Let me explain.
Build, buy, outsource, integrate? All of the above (but: pick your battles)
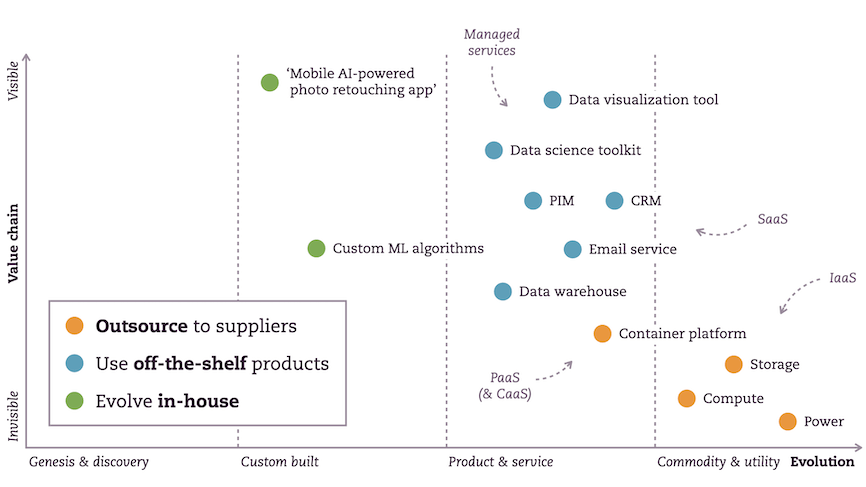
Let’s look at the choices the fictional organization behind this highly successful (but fictional, like I said) app has made.
In the image above, you see an example architecture of an AI-powered photo retouching app, broken down into its components and plotted on a Wardley Map. The y-axis shows us how valuable elements of the solution are to end users. The higher, the more visible a component is to them, and the more valuable they deem it: a user generally does not care if you use platform X or Y as long as their app works reliably. The x-axis is about the evolutionary stage of the components. Just-discovered technology, for example, will appear on the left, but the older it gets, the more it will shift to the right. Over a decade ago, container platforms were relatively new, so they would have been plotted much farther left than they are now.
At the top left, we see the mobile application users interact with daily. It uses custom algorithms running somewhere in the backend or the app itself. This functionality is by far the most customer-visible and valuable thing they own; that’s why it’s so high on the map. So, they want complete control: they design, develop, and deploy the app and algorithms themselves.
To further evolve the algorithms, their data scientists and business stakeholders need to gain continuous insight into their users’ behavior. The blue dots are the systems and services that help them collect, combine, transform, and finally visualize their user’s behavioral data using managed services, third-party tooling, and a hosting platform. They don’t need complete control here, so they opt to hand off its management to service providers. However, they do need control over integrating this part of their landscape.
Then there is the so-called boring stuff, at least from a software creator’s point of view, at the bottom right in orange: the critical infrastructure. Their customers do not care one bit if they manage this themselves. But like water and electricity, it is fundamental for everything built on top to work. So, they want to exert less control here: they don’t want to spend costly resources managing all this highly available, virtually infinitely scalable stuff. They want to leverage the years of experience of a party that knows how to run critical infrastructure while paying only for what they use. So they outsource this.
Here we have the first part of the answer to the so-called paradox of less control and more speed. Now let’s solve the integration part of this puzzle.
Integrating the solution: less control = looser coupling
Here is the same solution from an integration perspective.
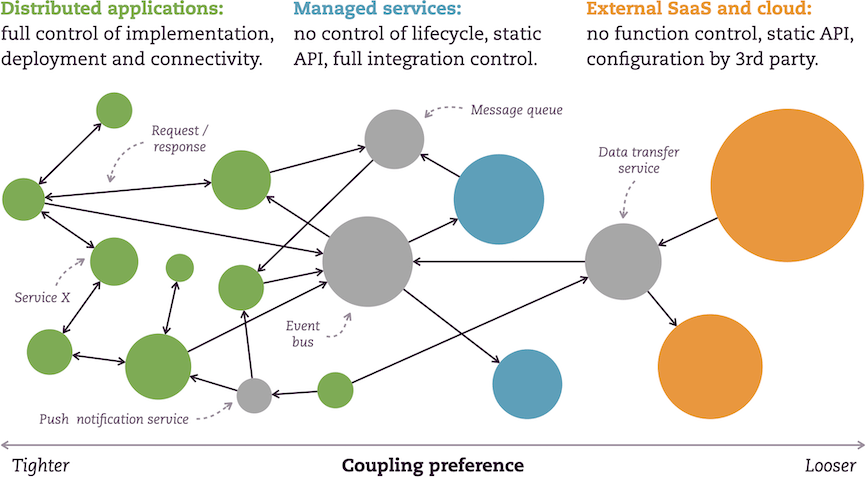
We are still looking at a mix of self-hosted applications integrated with managed, third-party services and externally hosted SaaS. At the infrastructure level, there is a mixture of public cloud, private cloud, or a private data center, and the magical SaaS infrastructure.
The (still fictional) AI-powered photo retouching app company smartly combines integration solutions to make something of these mixed ingredients. The general rule of thumb here is simple: the more control they have over solution lifecycles, the tighter they can couple them. And vice versa: less control, looser coupling.
On the left-hand side, there is all the stuff they control entirely. They integrate using direct connections, push notification services, and message queues.
In the middle are the managed services they employ. They use a central event bus, so they decouple the integration slightly more than on the left by introducing a highly configurable, flexible, but fast integration solution in the middle. It could be a serverless event router like Amazon Eventbridge or Azure Event Grid.
At the far end, on the right-hand side, in orange, are the external parts of our landscape: SaaS offerings, maybe another cloud, or externally hosted service. Since the photo app company has no control over them, they decouple these elements using data transfer services or an event bus at the edge of their specific hosting platforms. This way, the organization can still evolve its end-to-end solution, and the SaaS and external service providers can continuously update their offerings independently. In the case of an API or contract change, the AI photo app developers only need to change the data transformation logic, while the rest can keep running as before.
Now the speed-up-with-less-control paradox is resolved. Again, we need to realize that our landscape consists of groups of subsystems, grouped by their properties — in this case, the amount of evolutionary control the organization has over each solution piece. From this perspective, they can then integrate them using fit-for-purpose integration solutions. They still control their total solution, just not all its internals.
Excellent, but the story may not convince you entirely yet — the company, its users, and its success are fictional, after all. Let me try to convince you with a real-world example where I was closely involved.
OHRA: cloud-native development and integration from the trenches
OHRA, one of the Netherlands’ biggest directly writing insurance companies, asked Luminis to help migrate their application landscape from their on-premise data center to the AWS cloud. Their application landscape was large, with almost 1,000 integrations between internal and external services, clients, and databases. Did I mention the fixed deadline? About a year from the start. We helped them make it, partly thanks to the abovementioned integration strategy.
Most of OHRA’s moving parts are under their control, so they are integrated using a mix of direct messaging and message queues. When moving to AWS, we helped them mostly replatform the applications from application servers running Java applications to a managed Kubernetes cluster running containers. Much of OHRA’s data flows through third-party packages spread over their application landscape. So we employed the tactic we saw on the previous slide: loose coupling for SaaS integrations using data transfer logic at the edge and asynchronous communication with third-party apps installed in their application landscape.
A big help in making OHRA’s cloud migration deadline was their existing service-oriented architecture, an excellent stepping stone towards a more event-driven and, thus, cloud-native architecture.
Further reducing complexity and costs, improving agility
After migrating, the cloud provided OHRA with new opportunities to evolve its solutions. One example is the modernization of batch applications.
Previously, scheduled jobs were deployed on self-managed servers, running 24/7, even though most of them only actively did something for a few minutes to a couple of hours a day. In the public cloud, you should pay only for what you use, so I helped OHRA envision a more cloud-native and cost-effective way of creating short-running jobs.
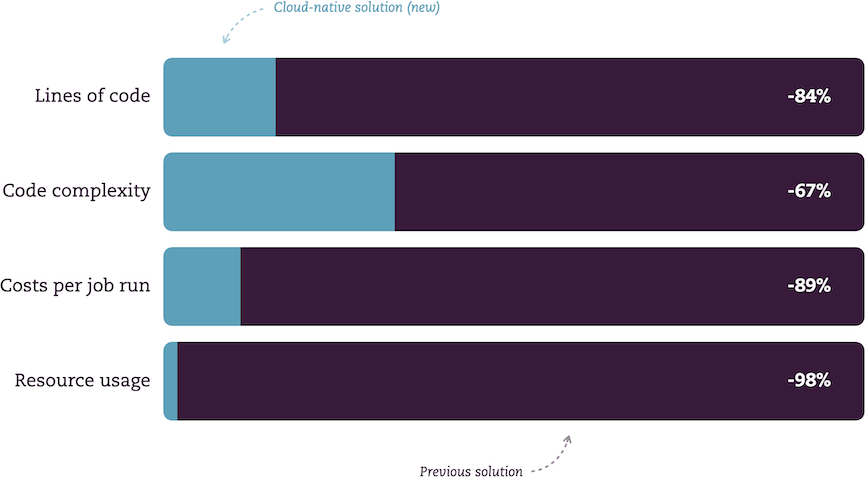
During two weeks, I led a team that re-architected an existing solution and delivered a modern, lean batch application: a distributed data processor made from a combination of serverless building blocks like Amazon EventBridge rules, Amazon SQS queues, and AWS Lambda Functions. As you can see in the image above, this drastically reduced the amount of code needed (and thus its complexity), the resources used, and the costs accrued.
OHRA can use this cloud-native way of working moving forward and enable their teams to free up time and resources, which they can then spend on stuff that will help the business grow its competitive edge.
One more time: the paradox resolved
So, now you have a complete, high-overview answer to the faux paradox of gaining speed while not having complete control. Allow me to recap.
First off, from a market perspective, companies are forced to move away from centrally controlled, neatly contained solutions running in their data centers towards integrating their locally managed custom building blocks with third-party software and externally hosted SaaS solutions.
There is a two-part solution to this problem.
The first part concerns being smart about spending valuable time and resources. Organizations require complete control of the software development and deployment lifecycle for the user-facing features they develop. Everything that powers this end-to-end solution — but is less visible or even completely invisible to the customer — can be hired as a service or bought as a product from a cloud provider.
The other half of the answer concerns being smart about integrating a fragmented landscape. I identified three groups, from fully controllable and evolvable elements to managed services and non-transparent SaaS solutions. Tight coupling is a good solution for distributed applications under a company’s control, but managed services and SaaS need looser coupling. Organizations can implement this solution by leveraging a combination of message queues, event buses, and data transfer services.
And thus, the paradox is dissolved!
Want to know more about what we do?
We are your dedicated partner. Reach out to us.