

RAG: splitter chain for proper chunks
RAG, short for Retrieval Augmented Generation, is a popular pattern for working with Large Language Models. In previous blog posts, I discussed the importance of chunking in combination with retrieval strategies for RAG. In another blog post, I wrote about semantic chunkers. Semantic chunkers can work better on smaller chunks. Therefore, I need a chain of splitters to get the right chunking strategy for those situations where one splitter is insufficient. With a chain, you can support chunking with a maximum of tokens and split each chunk semantically.
This blog post explains how the splitter chain works in the RAG4p project. The RAG4p-gui project provides a visual idea of the splitters at work.
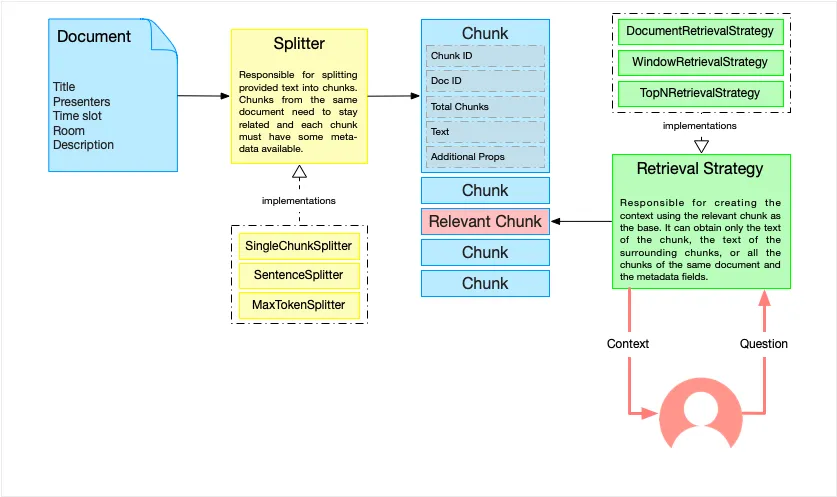
Recap: the purpose of a Splitter
With RAG, we ask an LLM to answer a question by providing it with the best context we can get. We use a retriever to find relevant text pieces, often using vector search.
A splitter cuts the bigger texts into pieces we can handle. Chunk is the name for such a piece. If a chunk is too big, it contains many different concepts. If it is too small, it will not have enough context. A strategy can create a better context from the relevant chunks found. A strategy can select chunks surrounding the relevant chunk, the WindowStrategy. It can also choose the complete document from the found relevant chunk.
The SentenceSplitter and the MaxTokenSplitter are the most common splitters in my workshops. However, we want something more. We want each chunk to have one specific semantic meaning. That is where the semantic splitter comes into play. We can ask the LLM to cut a large text into semantic pieces; the size is limited, though, and we often need more structure. Therefore, we cut the large text into chunks and extract semantic meaning from those chunks. To accomplish that, we need a way to use multiple splitters.
How do chunks relate to each other
Currently, each chunk has a document ID and a chunk ID. Together, they identify the document. With a chain of splitters, we get chunks being split into other chunks. Therefore, the chunk ID is now created from two chunk IDs. So, the first chunk of a document with id doc1 becomes doc1_0. For a second-level chunk, this becomes doc1_0_0. Each chunk knows how many chunks are available for that level. With the ID, we know all the significant chunks of the splitters’ hierarchy.
The SplitterChain implementation
The splitter chain must be a drop-in replacement for a splitter. Each filter must know how to act when it is not the first splitter of a chain. In that case, it receives the document and also the parent chunk. Below is a representation of what happens.
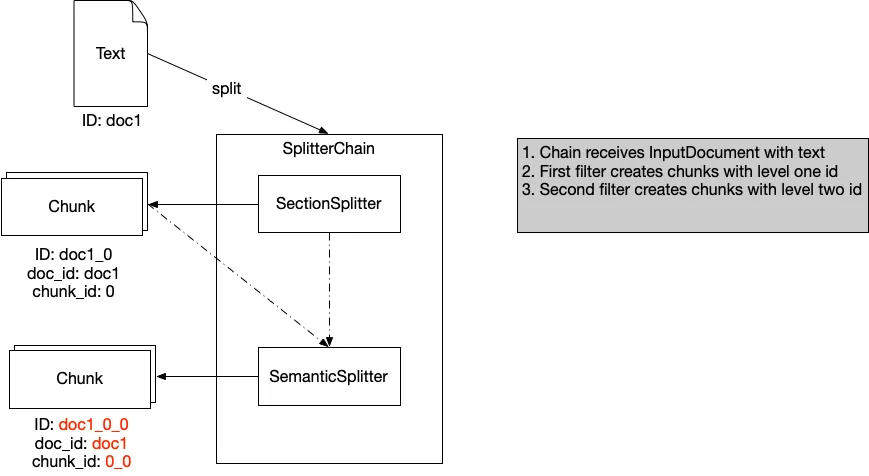
An essential choice is to store the chunks that are not the end product. If you store them, you also have a meaning for the bigger chunk. In general, we store only the highest and lowest levels of chunks. But in case of more than two splitters, you can also store the other in between. Below is the SplitterChain from the RAG4p project.
from abc import ABC
from typing import List
from rag4p.indexing.input_document import InputDocument
from rag4p.indexing.splitter import Splitter
from rag4p.rag.model.chunk import Chunk
class SplitterChain(Splitter):
def __init__(self,
splitters: List[Splitter],
include_all_chunks: bool = False):
self.splitters = splitters
if not self.splitters or len(self.splitters) == 0:
raise ValueError(
"At least one splitter must be provided.")
self.include_all_chunks = include_all_chunks
def split(self,
input_document: InputDocument,
parent_chunk: Chunk = None) -> List[Chunk]:
return self._split_current_splitter(
input_document=input_document)
def _split_current_splitter(self,
input_document: InputDocument,
splitter_nr: int = 0,
parent_chunk: Chunk = None)
-> List[Chunk]:
chunks = []
current_chunks = self.splitters[splitter_nr].split(
input_document=input_document,
parent_chunk=parent_chunk)
for current_chunk in current_chunks:
# We always add the first and last chunk, or all chunks
# if include_all_chunks is True
if splitter_nr + 1 >= len(self.splitters) or
self.include_all_chunks or splitter_nr == 0:
chunks.append(current_chunk)
# If we are not at the last splitter, we recursively call
# the next splitter
if splitter_nr + 1 < len(self.splitters):
child_chunks = self._split_current_splitter(
input_document=input_document,
splitter_nr=splitter_nr + 1,
parent_chunk=current_chunk)
chunks.extend(child_chunks)
return chunks
@staticmethod
def name() -> str:
return "SplitterChain"
Notice the recursive calling of the splitter function with the current node as the parent node. You can create a hierarchy splitter for a section, paragraph, and sentence splitter. You can also use a max token splitter in combination with the semantic splitter.
In the next section, you can see the splitters at work in a demo with the RAG4p-gui project, which heavily uses the RAG4p project.
Demonstrate the RAG4p-gui project.
References
Want to know more about what we do?
We are your dedicated partner. Reach out to us.