
Mastering State in Stateless LLMs
Large Language Models (LLMs) operate without inherent memory — they are stateless by design. The only “state” they recognise is your context in the current interaction. This context comprises your input messages and the model’s responses. The larger the context window, the more of your conversation the model can process at once. The LLM attempts to establish and maintain a relevant state for generating meaningful responses by parsing the entire context.
Throughout this blog, you follow an example of how the LLM helps you apply for a job. First, the LLM must know about your professional life and the vacancy you want to apply for. One way to achieve this is to instruct the LLM in the system messages about the information it should collect and prompt it to ask the right questions to build a complete picture. While this approach is highly flexible, it can also lead to unpredictable results due to the open-ended nature of the questions. For instance, the LLM might ask irrelevant or redundant questions or fail to focus on critical details, making it challenging to achieve consistent outcomes.
The alternative solution
The training Building an AI-Powered Game from Deeplearning.ai presents a distinct approach to state management. It introduces a JSON structure to represent the required state of a game. One call extracts changes to the state, while the subsequent uses the updated state to respond to the user’s action. For example, the state contains an inventory. The first action is to pick up a stone. Inventory action is “stone +1”. Next, the action is to throw away the stone. Inventory action is “stone -1”. Without a stone in the inventory and trying to throw it away again, the LLM will respond with a message that you cannot throw away a stone you do not have.
This structured and iterative process inspired the design of my Job Application Writer tool.
Overview of the solution
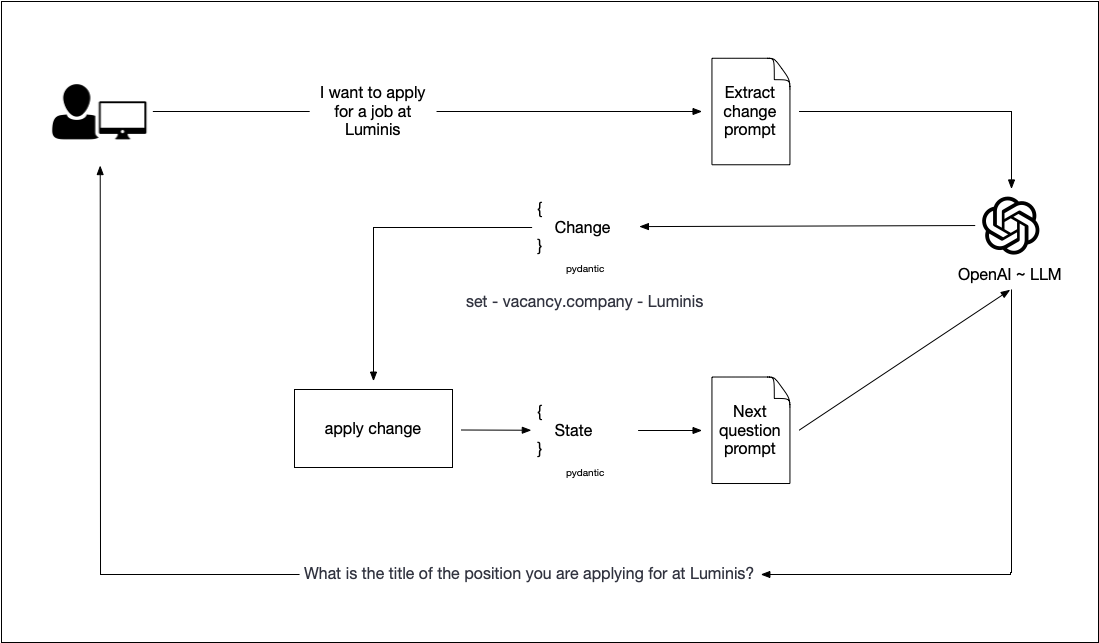
This shows the multi-step approach of the solution for a stateful LLM. The first step extracts the changes, and the second step uses the state to find the missing information and formulates a question to obtain more information.
Framework support
You can work with a structured state object using regular LLM interaction. Regular means asking it to produce JSON and telling it to receive JSON. With some framework or client support, it becomes much more manageable. The code samples contain code using the beta part of the OpenAI Python client. When writing this blog, Ollama also released a structured output feature. The Ollama feature looks similar to the one from OpenAI.
The OpenAI Reference – The Ollama reference
Structured output ~ The first interaction with the LLM
People who have worked with LLMs from the start know how hard it can be to make an LLM return a JSON-formatted response. With recent client libraries, specifying an LLM call response schema has become much easier. In Python, you can use Pydantic to define your structure. That way, the response is a TypeSafe object. Check the following code block for an example. Note the use of the beta client part and the response format.
def extract_state_change(client: OpenAI, state: LLMState, user_message: str) -> StateChanges:
chat_completion = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[
{"role": "system", "content": system_message_extract},
{"role": "user", "content": f"{user_message}\nstate: {state.model_dump_json()}"},
],
response_format=StateChanges,
)
logger.info(chat_completion.choices[0].message.parsed)
return chat_completion.choices[0].message.parsed
class StateChange(BaseModel):
change: Literal['set', 'append', 'remove']
field: str
value: str
class StateChanges(BaseModel):
changes: List[StateChange] = None
def add_change(self, change: StateChange):
if self.changes is None:
self.changes = []
self.changes.append(change)
Below is the system message in the prompt. Note how the structure of the model is provided. The code uses the model_json_schema() command of a Pydantic object.
system_message_extract = f"""You are a CV writing assistant. You need specific
information to help me write a my CV. You keep track of the information I
provide you in a state object.
You can ask me questions to get more information. I can ask you to remove
items from the state. Your goal is to gather as much information from me as
possible. You tell me the change you made to the state. If no change is made
you return {StateChanges().model_dump_json(indent=None)}. Else the change is
a json document with the structure: {StateChanges.model_json_schema()}.
The format of the state has the next schema:
{LLMState.model_json_schema()}
"""
Below are a few example outputs of the extract_state_change method. Check the DEMO section for a running demo, including the input, output and extracted changes. Look at the GitHub repository to find the unit test for the code that accepts and applies these changes to the current state. The diversity of the value and the field name needs some specific code. Note that sometimes the value is a literal, and other times it is a complete JSON structure. For the field, we have nested fields and list fields that we need to create, change or append to.
StateChange(field="vacancy.title", value="Engineer", change="set")
StateChange(field="experience.previous_roles",
value='{"title":"Software Engineer","company":"Capgemini","years":7,"description":"Worked on various projects across different domains"}',
change="append")
StateChange(field="experience.previous_roles[1].title", value='Search Engineer', change="set")
A new question ~ The second interaction with the LLM
In the next step, the changed state is provided to the LLM. With the state, a prompt asks the LLM to come up with the following question to complete it. Below is the prompt for this step. Note how we pass the state, this time, not the structure but the content, using the Pydantic method model_dump_json().
system_message = """You are a CV writing assistant. You need specific
information to help me write my CV. All the current information about the
vacancy and my experience is available in the state object.
Ask me a question about the vacancy or my experience to add required
information for the vacancy and my experience. If you have enough information
to write the CV, tell me you are ready.
"""
def ask_for_next_step(client: OpenAI, state: LLMState) -> str:
chat_completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": f"state: {state.model_dump_json()}"},
]
)
return chat_completion.choices[0].message.content
The LLM Loop
In the first step, the LLM extracts the change to the state based on the information provided by the user. In the second step, the LLM uses the new state to determine the question for more details. Below is the code for this loop.
def main_loop(client: OpenAI, state: LLMState, historic_changes: StateChanges, user_message: str) -> str:
changes = extract_state_change(client, state, user_message)
for change in changes.changes:
historic_changes.add_change(change)
set_nested_value(state, change)
return ask_for_next_step(client, state)
The remainder of the code sets the value and the GUI for the demo. The code is in the GitHub repository.
Demo
Concluding
That is it. You now have a running example of managing state in your LLM application. Combining Python and Pydantic gives you the schema or structure of your state. With OpenAI and Ollama client support, managing the state is possible.
References
Want to know more about what we do?
We are your dedicated partner. Reach out to us.